ICML 2026
IDLM: Inverse-distilled Diffusion Language Models
IDLM distills pretrained Diffusion Language Models into few-step generators, reducing inference steps by 4x-64x while preserving generation quality.

Key Innovations
- Inverse distillation for tokens. IDLM adapts inverse distillation from continuous diffusion models to discrete language generation.
- A valid optimization target. The method addresses non-uniqueness in the inverse objective by establishing a uniqueness guarantee for the discrete setting.
- Stable training relaxations. Gradient-stable relaxations make backpropagation through discrete token spaces practical.
- Fast few-step sampling. Experiments across multiple DLM teachers report a 4x-64x reduction in inference steps while maintaining entropy and generative perplexity.
Abstract
Diffusion Language Models have become a promising route for text generation, but their iterative sampling process can make inference slow. IDLM extends inverse distillation to this discrete setting, using a pretrained DLM as the teacher and training a student generator for substantially fewer sampling steps.
The paper tackles the theoretical issue of non-unique inverse objectives and the practical difficulty of unstable discrete-space gradients. Its solution combines a uniqueness result with differentiable training relaxations, yielding a post-training framework that accelerates DLM inference while preserving core quality metrics.
Text Generation: DLM vs. IDLM
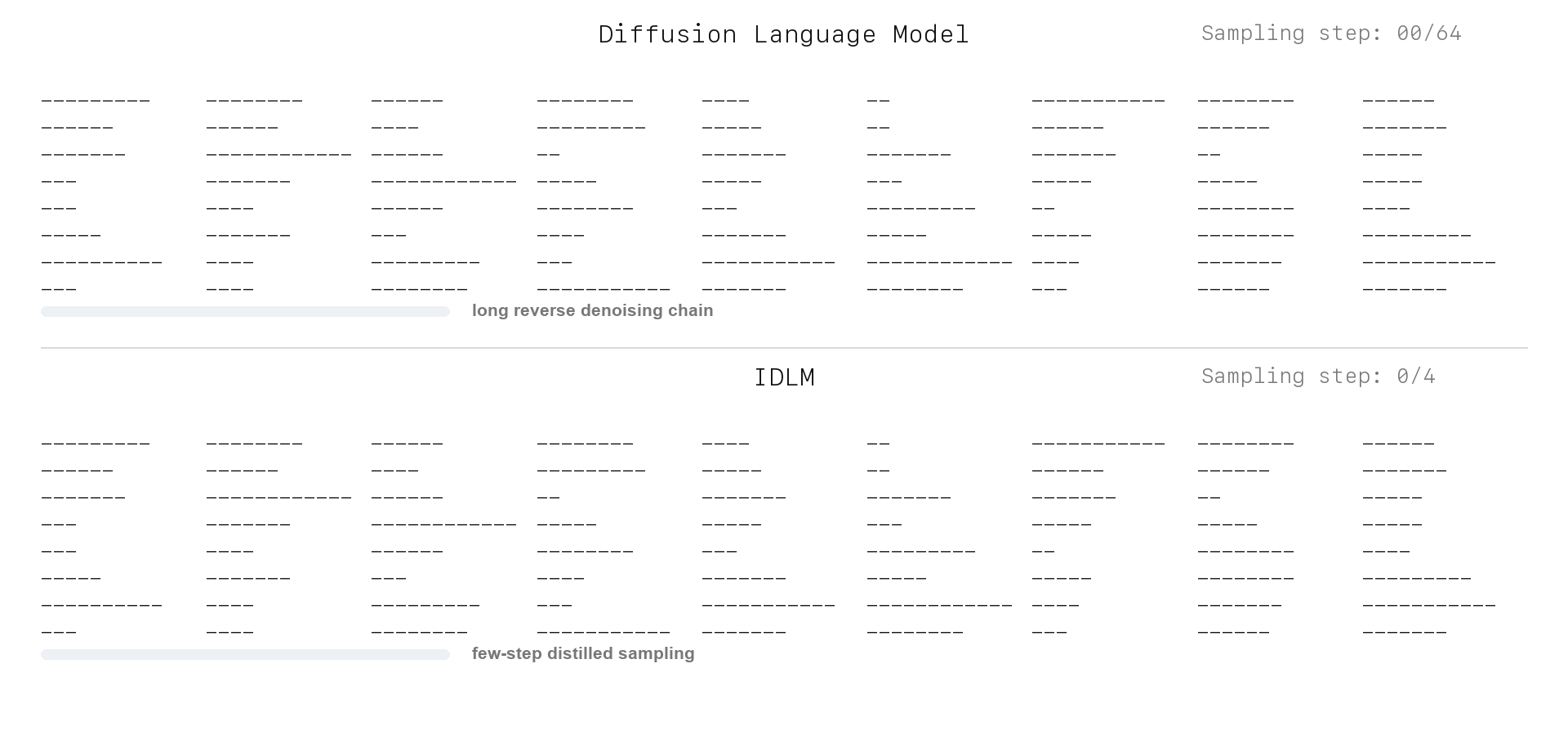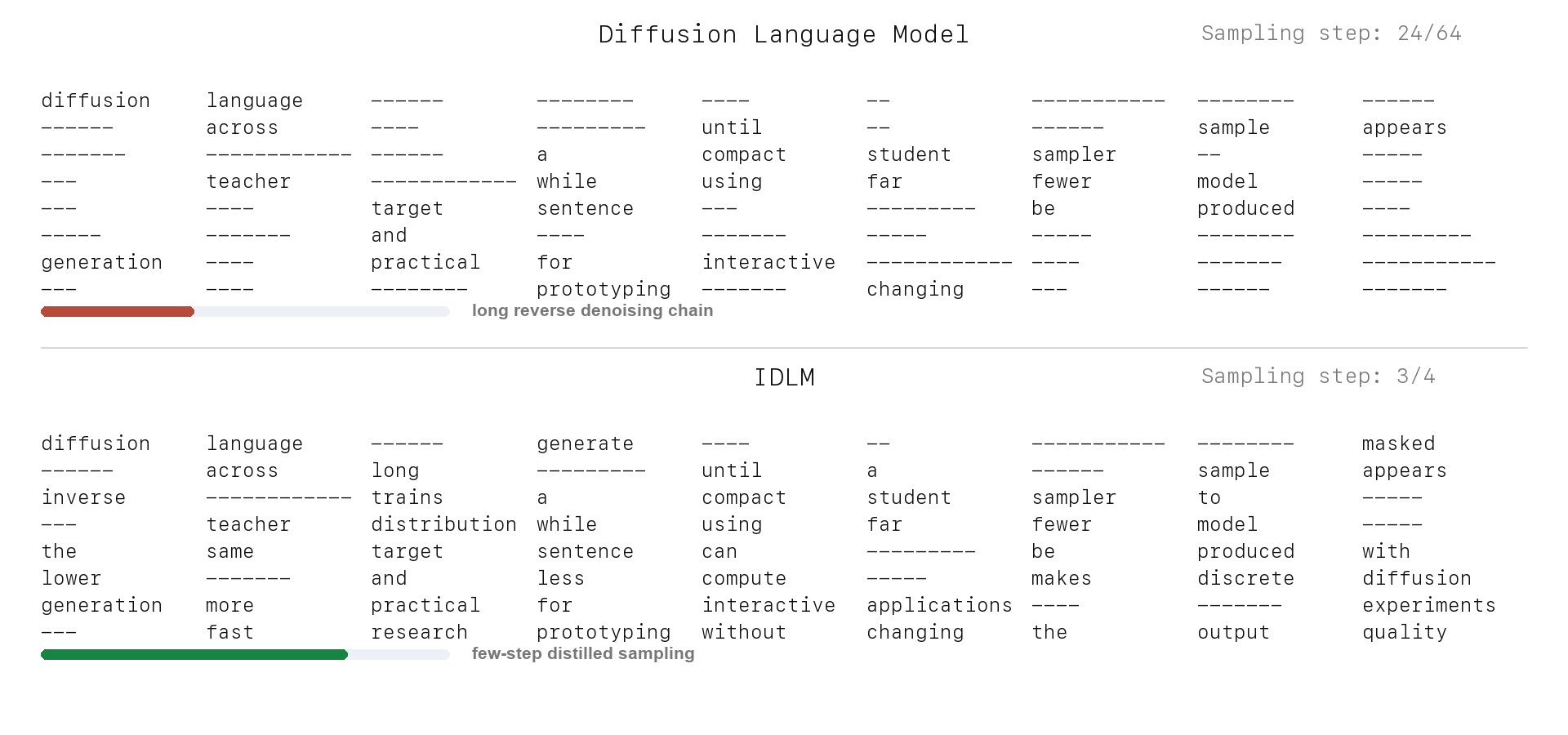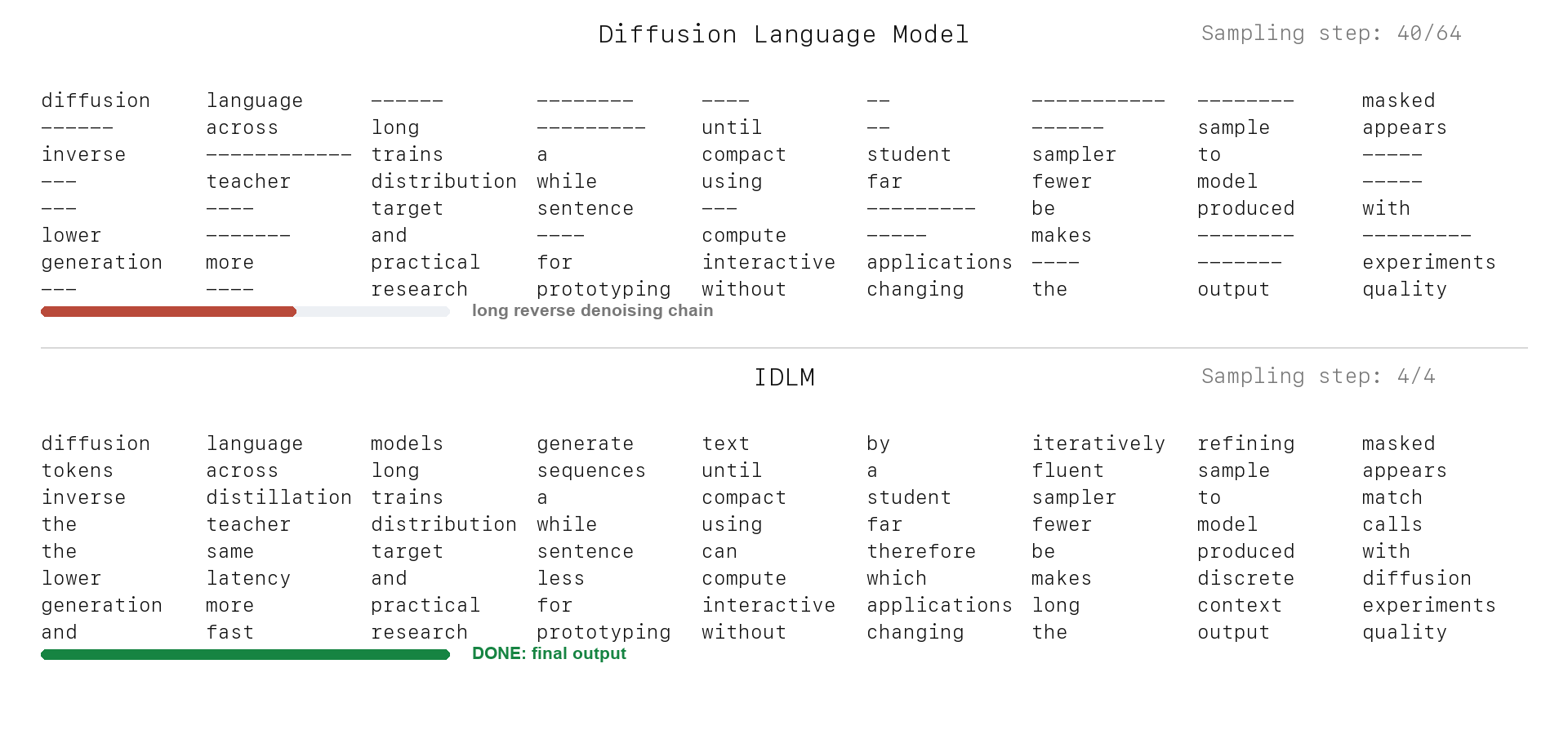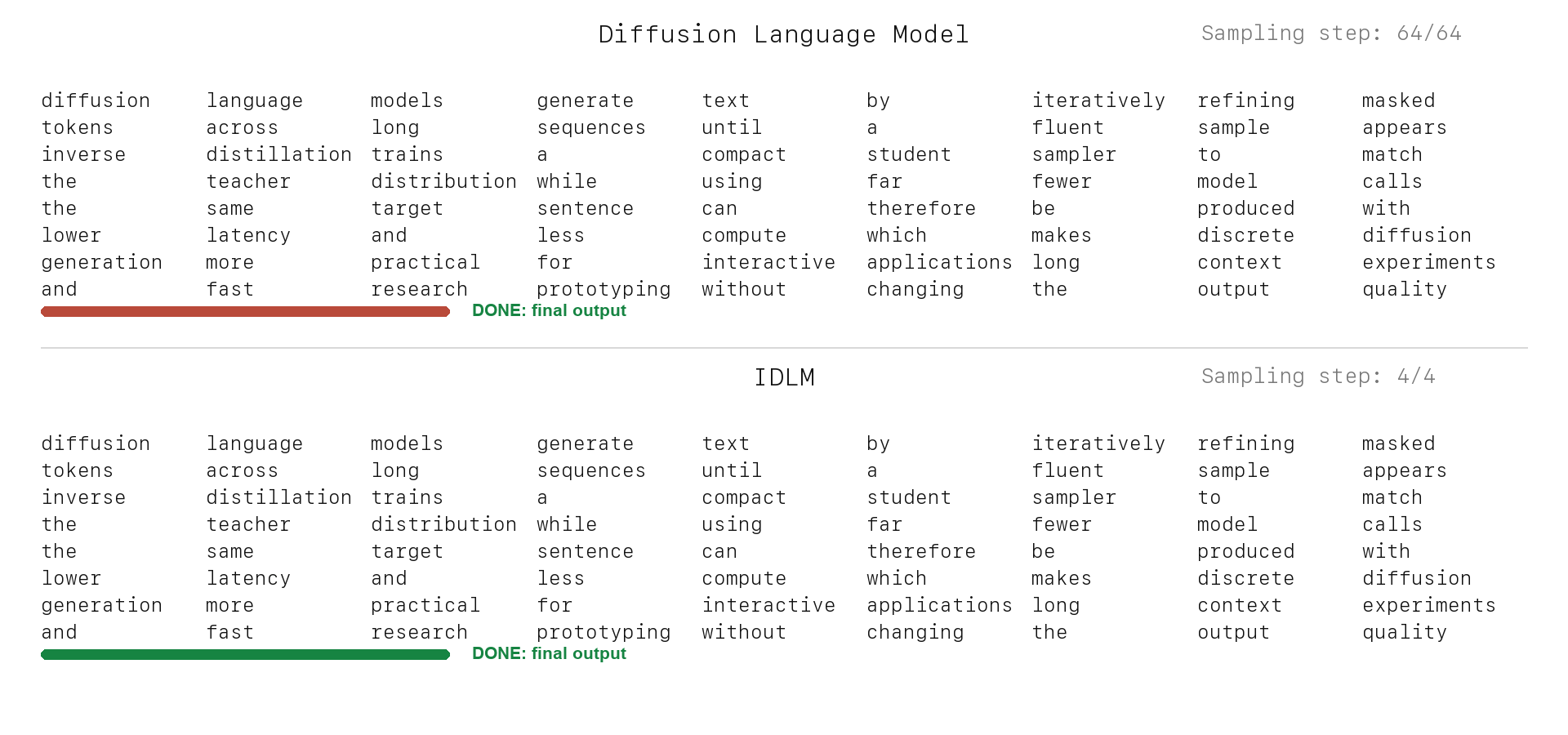
IDLM keeps the discrete diffusion teacher's quality target, but compresses sampling into a few-step generator for substantially faster inference.
BibTeX
@article{li2026idlm,
title={IDLM: Inverse-distilled Diffusion Language Models},
author={Li, David and Gushchin, Nikita and Abulkhanov, Dmitry and Moulines, Eric and Oseledets, Ivan and Panov, Maxim and Korotin, Alexander},
journal={arXiv preprint arXiv:2602.19066},
year={2026}
}